
Managing Measurement Data
Many tools are available to assist with managing these collections, or associations
Background
Collecting data is so easy these days. Sometimes, the hard parts are setting up the equipment and conditions before you measure the data and figuring what to do with the data after it’s measured!
Once the data are measured, many people struggle with the resulting collection of data and how to associate it with the particular experiment or test. For example, it’s typical that all the measurements from a test are placed into a file folder named appropriately to describe the test conditions. But this method of creating such a collection, or association or grouping, complicates even simple analysis needs. For example, when needing to plot the peak stress against the pressure to which the sample was subjected, a special routine or method must extract the stress data out of all the test folders and collect the points into an array.
Many tools are available to assist with managing these collections, or associations. Some tools are within the National Instruments (NI) product line and some outside. Databases (DBs) are common throughout. Let’s review a few and discuss some of the pros and cons of each.
SQL
SQL is an acronym for Structured Query Language, but it is now synonymous with the DBs that use SQL to read, write, and search for data. A SQL DB stores data as a collection of records, each consisting of a row of elements with specific data types. Supported data types are scalar in nature, such as a floating point value or a string. Some SQL DBs support BLOBs (Binary Large Objects) to allow arbitrary data types as a single BLOB.
Records are stored in tables. These tables are two-dimensional and so they are good for managing rows of multi-column records.
SQL is designed to support relational DBs, which means that a record in one table can be related to one or more records in one or more other tables.
Figure 1 – Records in multiple tables are linked with a common key value
The records in different tables are related by using a key (e.g., an index). For example, a Table X record has the same key value as a key in Table Y. To access all the related records, these tables are connected together in what SQL calls ‘joins’. Some joins make very big tables, especially when the key relations are one-to-many.
In Figure 1 above, the top (MainTable) table links to the other tables (AgeTable and GenderTable) via the ID field. A table can have many records with the same ID in order to accommodate a situation where Alice has many tools. Then, to find all the tools (in ToolsTable) that are associated with Alice, you would execute the following SQL statement:
SELECT MainTable.First, MainTable.Town, AgeTable.Age, ToolsTable.Items
FROM (AgeTable INNER JOIN MainTable ON AgeTable.[ID] = MainTable.[ID]) INNER JOIN ToolsTable ON MainTable.[ID] = ToolsTable.[Tag]
WHERE (((MainTable.First)=”Alice”));
The key here is to perform a JOIN (INNER not OUTER) to find all the combined records and then filter by the name “Alice”.
Pros and Cons
SQL DBs are the industry standard. The query engines have been highly developed and can be very fast, depending on which vendor’s SQL DB you are using and the structure of the DB tables.
I’m not sure of the statistics, but I essentially certain that there are far more SQL DBs on the planet than any other type of DB. All the big DBs used by online retailers are SQL-based. There’s a reason that IBM, Oracle, and SAP are big companies.
SQL is so ubiquitous that free versions are available, such as Microsoft’s SQL Server Express and MySQL to name a couple. These free DBs come with restrictions, of course, such as the 10 GB size limit for SQL Server Express and the OpenSource license with MySQL. But these restrictions are not generally an issue for single person or team use.
On the downside, SQL tables are not flexible to changes in the design of the table. When adding or removing a column from a table, the DB has to deal with the empty rows elements if you add a column and the possible breakage in relationships between tables if you delete a column in another table.
In addition, since SQL is designed for scalars (BLOBs are a kludge), SQL DBs are not well suited to many typical measurements, such as 1D data (e.g., waveforms) and 2D data (e.g., images or acquired data that is unevenly sampled in time). Of course, it will not do well with other non-rectangular collections of data sets and multi-dimensional data types, since these collections don’t fit well into tables.
Associating Data
You can create records that describe your test, experiment, process, or machine and all the associated data files and conditions for those data. Then, when you want to locate a particular experiment or set of experiments, you can search against the conditions and locate all the data.
Viewpoint uses Microsoft SQL to help our clients manage their test data and tracking parts through manufacturing (i.e., WIP). PostgreSQL is also used on the Linux-based OS for LabVIEW RT on PXI and cRIO application targets.
NoSQL
NoSQL refers to databases that do not use the relational tables inherent in a SQL database. Instead, these databases store data in an unstructured manner which allow flexible linkages between descriptions of data elements.
A specific type of NoSQL employs RDF, which is an acronym for Resource Description Framework. An RDF database is built on a directed graph, which describes free-form links between data objects. The Figure 2 below illustrates a directed graph for “Tom & Jerry”.
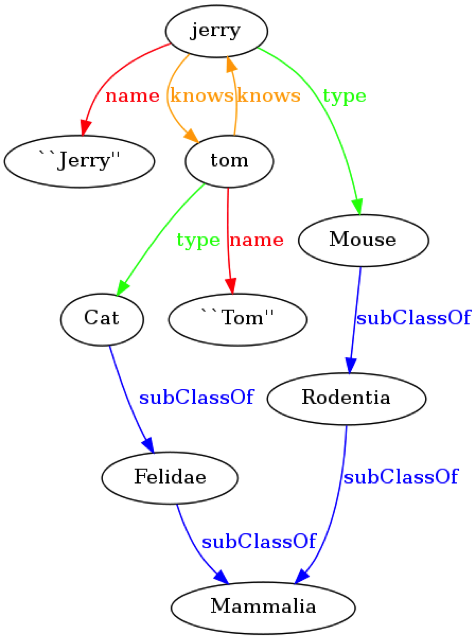
Figure 2 – RDF directed graph
These links are formed by “triplets” that describe the subject, predicate, and object. For example, at the top of the figure above, the triplet is (Jerry, IsType, Mouse).
You can see how flexible this method is for a DB. There are no restrictions that the data fit into a table structure. Plus, the items in the ellipses can be any data type. In fact, the description of the data type can be part of the DB.
RDF DBs are available from Mulgara, Apache, and others. Some have created an RDF DB using a SQL DB, which in concept is a table with few but very long columns (i.e., many rows), such that each row is something like an object with a link to another object. Faster searches are possible using different data structures, and that’s how RDF DBs are built.
Viewpoint has an RDF DB called Aperio. This framework uses Mulgara and has helped our clients manage their extraordinary data and flexibility needs. It’s sometimes used alongside the StepWise test executive.
Pros and Cons
RDF DBs are extremely flexible, handling unlimited types of data and being very elastic to content change. For example, adding new or removing old information to any object is as simple as adding a new or removing an old link. Queries will still work by returning more or less results.
Of course, this flexibility typically makes RDF databases slower than SQL DBs. Also, they are not an industry standard, by any means, but they have been used successfully in important applications.
Associating Data
Similar to SQL, you can create links that describe your test, experiment, process, or machine and all the associated data files and conditions for those data. The benefit of using RDF is that it’s easy to add new information long after the test or experiment has been run. Our clients that use Aperio do so because of new device history information, such as field returns, or new data analyses that they had no idea was important initially.
SCADA
SCADA is an acronym for Supervisory Control and Data Acquisition. I’m not sure of the statistics, but I’m fairly certain that SCADA DBs are the second most widely used type of DB in the world. These DBs collect periodic data from slow measurements across many channels and are typically used to monitor assets such as machines and processes for performance data. SCADA DBs are widely used in improving processes and reducing maintenance costs.
SCADA DBs are unique in that they are optimized for storing scalar measurements from multiple sensors, real and calculated. Each sensor is typically collected at their own unequally-spaced time intervals. They also typically have built-in data compression by allowing measurements to use deadbands before storing data: data are saved only after they change by X% or have not been logged in M minutes. Most SCADA applications refer to these DBs as “SCADA historians”.
Since these DBs hold data from potentially widely separated assets, such as the temperatures of each pump in a refinery, SCADA DBs are designed to have multiple concurrent connections from various data servers each with 100s, 1000s, or even 10000s of sensors, often referred to as tags. It’s possible to have millions of tags.
Many vendors in the industrial control market make SCADA databases. Some good examples are PI from OSISoft, Proficy from GE, Citect from Schneider, Citadel from NI, InTouch from Wonderware, and many, many others – really many others from both big and small companies. They are all proprietary.
Pros and Cons
SCADA DBs are great for storing very large numbers of channels (tags) over long periods of time (years or decades). Many have direct support for pulling channels from PLCs tags. And the historian data retrieval and review tools are well done and refined.
However, the data updates into these DBs are generally very slow compared to DAQ. Once per second is common. This restriction makes sense since, in aggregate, there are possibly 10s or 100s of thousands of tags per second being pushed into the DB from many sources. SCADA DBs can be expensive due to the typical plant-wide installation and they are proprietary so that extracting data into an application outside the vendor’s historian is sometimes tricky.
Associating Data
SCADA DBs are best suited to associating data by the mere fact that they excel at merging data from huge numbers of sensors, real or calculated. All the data is in one location and queries are typically relative to sensor and time.
DataFinder
NI has a cool product called DataFinder that scans for properties in many types of data files. Based on search criteria on those properties, such as shown in the figure below, you can locate a subset of files.
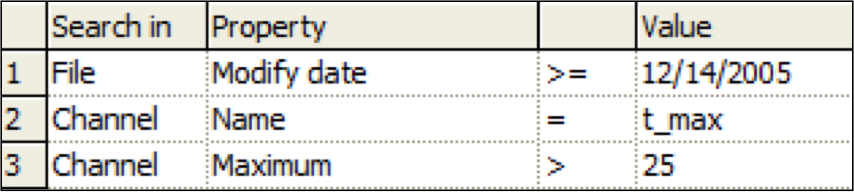
Figure 3 – DataFinder property search
Properties are categorized into file, group, and channel. File has properties such as name, time, date, and so on. Group has properties such as name, description, and so on. Channel has properties such as units, minimum value, maximum value, and so on. Custom properties are also available.
DataFinder is easily accessed from DIAdem, which is like a super-Excel for processing waveforms and reporting results. Check out www.ni.com/diadem. You can also use DataFinder in LabVIEW with the DataFinder toolkit.
DataFinder comes in a server version, which can index files across multiple computers and allows access by multiple users. It also comes in a “personal” version which only runs on your local computer.
Pros and Cons
DataFinder makes it easy to find waveforms using its property search capabilities. It’s pretty fast since the indexing (scanning) of all the file properties is done in the background and hence is ready when you are. In addition to native support for NI’s TDMS file format, it supports many standard file types, including CSV, DASYLab, dBase DBF, Agilent InfiiiVision BIN, Matlab MAT, Tektronix WFM and other types of files, and many types of Yokogawa files.
However, it only deals with waveforms and the properties have a limited amount of customization.
Associating Data
DataFinder is designed to help associate waveforms. It has the ability to locate multiple waveforms across various folders based on property comparison criteria.
Summary
There are many ways to associate data in a database to assist you in managing datasets collected from multiple machine, tests, experiments, and processes. The choice typically is made based on the amount of flexibility you need and the number of sensors involved. If you’re looking for help managing your measurement data, check out our capabilities and reach out if you want to chat.
Deep into learning mode? Check these out:
- Custom High Speed Data Acquisition Systems with LabVIEW
- LabVIEW OOP Example – Measurement Tool Chest
- LabVIEW-based Test Executive Software
- Making Good Measurements for Automated Test
- How to prepare for when your test team starts to retire
- Practical manufacturing test and assembly improvements with I4.0 digitalization
- What to do with your manufacturing test data after you collect it
- 5 Keys to Upgrading Obsolete Manufacturing Test Systems
- How Aerospace and Defense Manufacturers Can Make the Assembly and Test Process a Competitive Advantage
- 9 Considerations Before you Outsource your Custom Test Equipment Development
- Reduce Manufacturing Costs Report
- Improving Manufacturing Test Stations – Test Systems as Lean Manufacturing Enablers To Reduce Errors & Waste